從“天鏡”大模型透視馬上消費自主性生存法則觀點
2023,堪稱大模型元年。
2023,堪稱大模型元年。
年初ChatGPT有如平地驚雷,炸開了大模型的應用賽道。但有意思的是,一直熱衷于科技賦能的金融行業在大模型的開發上卻遲遲未有突破。
直到今年8月,馬上消費拔得頭籌,其自主研發的“天鏡”大模型上線,全國首個上線的零售金融大模型方才問世。這一開發和上線速度不僅超過了A股上市大行,也超過了阿里云、騰訊云這樣的科技巨頭。這為整個行業的發展提供了很強的標桿意義。
在過去8年的時間里,馬上消費作為一家沒有強勢股東的數據供給、流量加持和外部技術助力的消費金融機構,不僅做到了穿越周期、風雨不倒,云銷雨霽之后,還能保持優異的增長速度和創新能力。這與其長期深耕消金這一垂直賽道不無關系,當然,更重要的是,在科技這樣的資產密集、技術密集領域,馬上消費從不因為“重”就假手于人,而是堅定地、矢志不移地進行長期投入。究其根本,馬上消金所仰賴的生存密碼離不開三個字:自主性。
1
探路:堅定自研
金融賽道的大模型開發進程較想象中緩慢不少,原因有二。
首先,金融行業最重要的兩大特征:資金密集度高、風險敏感度高。在經濟大環境承壓的背景下,金融監管對于合規經營反復強調,這讓金融行業的創新探索,步調格外謹慎。
其次,金融行業大模型探索面對的是復雜場景,科技巨頭們在一些垂直領域掌握的數據并不具備絕對優勢,相較而言,在垂直行業的頭部機構反而更有可能掌握著更加專精的數據和開發經驗。
“天鏡”大模型在上線之前,已經在營銷獲客、風險審批、安全合規等零售金融典型場景落地。
馬上消費人工智能研究院高級研究員李寬告訴十字財經,馬上消費對大模型的價值定義主要聚焦在三個點:匯聚群體智能、喚醒沉睡知識和眾創數據價值。
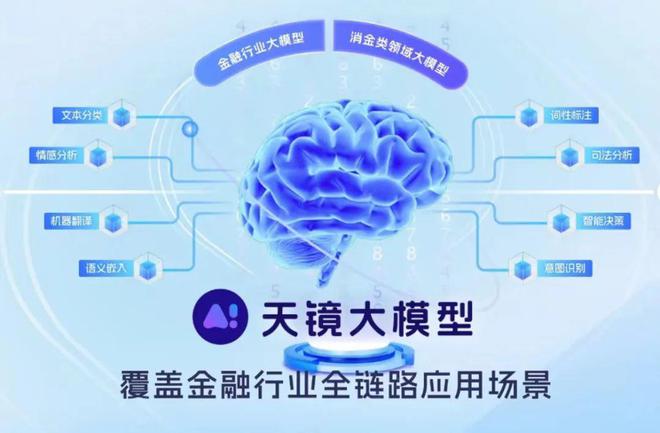
“智能坐席服務目標明確、場景清晰、工作量數據量也很大,是目前大模型運用最成熟、落地最深的應用場景,也是最能體現‘匯聚群體智能’的服務領域。”李寬補充,“傳統的AI需要人工參與配流程、配話術,大模型大在參數量和數據量,通過學習優秀人工的對話數據,在黑盒中完成訓練,能夠用擬人化的自然語言隨機應變地與客戶進行交流,話術不長,適配場景,客戶體驗很好。”
迄今為止,大模型實際投入運營已6個月,從目前累計的運行數據來看,“天鏡”大模型的意圖理解準確率達91%,相較于傳統AI的68%有大幅提升;客戶參與度61%,也遠高于傳統模型43%的參與率,和人工坐席平均57%的水平。
從馬上消費的業務規模來看,基數已經很大。最新數據顯示,馬上消費合作金融機構超200個,合作商戶超100萬,其自主運營的APP“安逸花”,目前日活躍用戶超160萬人次。這意味著,在效能方面哪怕是提升個位數的百分比,也能帶來相當大的社會效益。而效率的大幅提升為研發帶來了正向反饋,進一步推動大模型產品的后續打磨。
而李寬提及的“喚醒沉睡知識”和“眾創數據價值”則是馬上消費要進一步探索的方向所在。
根據李寬的介紹,所謂“喚醒沉睡知識”,主要是針對非結構化的文檔,表現形式眾多,比如規章制度,技術方案,會議紀要,驗收報告,匯報材料等企業過往經營形成的知識沉淀。“雖然現在企業基本上都做到了文檔的數字化,但仍然面臨著檢索不便、無法對有效知識充分利用的問題,‘天鏡’大模型就能夠很好地解決這些問題,把文檔給到大模型之后可以直接提問,獲得答案。”李寬表示。
眾創數據價值則是針對結構化的數據庫表的利用和分析,當下,企業的大量經營行為都涉及數據分析工作,而結構化的數據庫表需要數據分析人員手動生成SQL,‘天鏡’大模型上線后,數據分析人員只需用自然語言描述數據需求,大模型就能直接生成SQL和圖表,大大節省了數據分析人員的工作量,降低了數據使用門檻。
在馬上消費的“天境”大模型發布之后不久,螞蟻、騰訊云面向中小金融機構陸續發布了開源金融大模型應用。
事實上,對大多數中小金融機構而言,要快速實現大模型應用的落地,選擇開源大模型無疑是更具效率和性價比的方式。對這一點,馬上消費也十分清楚。
“相較而言,自研大模型無疑是一條更為艱難的道路。需要投入數倍于前者的時間、人力、財力,其中甚至有很多資源注定會被虛擲。”李寬表示,“開源大模型在使用階段也會面臨許多挑戰,比如領域適配性、訓練效率、推理速度等,而我們自研的大模型是在零售金融這個垂直領域做了專門的適配,用自有數據進行訓練,擁有更專精的領域匹配能力,長期來看,也能為將來贏得更強的技術自主性,為公司的長遠發展構筑更高的競爭壁壘。”
“自主性”不僅是過往8年發展歷程的總結,也是未來征程的注腳。
沒有傘的孩子更要努力奔跑。因為明白這個道理,自2015年成立以來,馬上消費每年都在持續大手筆地進行技術研發投入,迄今為止,已累計投入33億元,申請發明專利超1500件,自主研發出1000多套系統,研發團隊超2000人。這樣的投入規模和研發陣容在行業并不多見。
如今,大模型已經是一個高端玩家的賽道,資金實力、數據沉淀、技術儲備缺一不可,高筑墻、廣積糧的好處已然呈現。
2
往何處去:安全合規、數據治理
金融大模型的構建是一個系統化工程,需要以實際需求為驅動,逐層從基礎設施、模型算法,向場景化應用、軟件開發修筑起一座大廈,而這座大廈的地基是安全合規。
對金融行業而言,安全合規是一切創新與探索的前提。馬上消費首席信息官蔣寧在大模型發布之際表示:“希望在任何情況下,它給客戶的回答都是合規的,并且在任何不可預期的情況下它的結果是穩定的。”
這既是一個期望,也是一個任務。
馬上消費人工智能研究院創新研究部負責人馮月介紹稱,通常大模型安全是兩方面的,一方面是其生產內容本身的安全性,另一方面是在金融行業安全合規上,大模型有什么進一步的賦能。
關于大模型本身的安全,由于大模型本身是生成式模型,其生成內容天然帶有不確定性,因此本身就涉及合法合規問題,也即行業里常說的“內容安全”問題,在技術領域里也稱為“價值觀對齊”問題。
對于這類問題,目前是雙管齊下,一是基層大模型本身在訓練過程中就應該使用價值觀正確的、內容安全的訓練語料,提供正直、善良而非邪惡的基座,這依賴于訓練數據的篩選;二是應用方應在使用時級聯一套內容安全算法,對結果進行涉黃、涉暴、涉政等常見違法內容管控,在觸發時進行攔截,這依賴于管控算法本身的訓練。
關于大模型的安全應用,金融安全通常指的是合法、合規和經營風險規避三個部分。合法針對的普世的國家法律問題,這類問題在企業的表現可以是合同審核問題;合規針對的是專業的監管機構的規定、建議等問題,這類問題可能是信息化建設、隱私保護建設等問題;經營風險規避針對的是企業經營本身所產生的結構性風險,這類問題在企業的表現可以是欺詐的發現、員工的行為管控、客戶的投訴咨詢等。
如果說上述方向是企業未來的發展命題,數據治理的未來則是值得整個行業探討的話題。
“中文數據的通用大模型的效果要差一些,寫高質量的中文語料和相應數據建設需要行業的共同努力,也需要時間。”馬上消費技術部專家表示,“此外,《個人信息保護法》出臺以后,對于數據的運營和流通,外部監管和法律約束變得非常嚴格,大模型需要大量數據喂養,更大發揮價值的話,一定要想辦法打通同行業甚至跨行業的數據壁壘。在數據治理方面,每個企業都有自己制度設計和管理方式。對于數據流通的探討從來沒有停止過。聯邦學習、隱私計算、數據的可用不可見都是很好的探索。這些是需要全行業共同努力的事情。”
科技的本質是賦能,無論多么先進的技術手段,最終都必須落地到業務端形成正反饋,否則就毫無意義。
前途光明,道路崎嶇。但往往,人跡罕至的道路才能抵達最美的風景。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
