從WAIC數據爆發看騰訊ima:AI原生應用如何重構知識生產力智能
有用、可靠的信息流動起來,會怎樣?
上線半年多
環比增長208%
2000萬+
……
這是7月27日世界人工智能大會(WAIC)上,騰訊信息服務線負責人何毅進發布的ima的成績單。

丨騰訊信息服務線負責人何毅進在WAIC演講現場
這份成績單,不僅印證了“活知識庫+大模型”融合路線的爆發力,更揭示了騰訊在AI原生應用戰場的布局。從微信搜一搜的"AI搜索"到混元大模型的開源,從四大產品線整合到知識號生態的搭建,騰訊正通過ima這個抓手,試圖重新定義信息獲取、知識管理與內容創作的底層邏輯。
一、從工具到生態:ima的進化論
何毅進在演講中提到ima“三層鏈路”:底層知識庫支持文檔、圖片、公眾號等多元內容形態,用戶可自主構建個人知識體系;中間RAG層確保知識被精準檢索調用,解決傳統大模型“幻覺”痛點頂層應用層則通過多模態創作、腦圖編輯等工作臺能力,將靜態知識轉化為生產力。
不難發現,ima并非孤立的工具,而是騰訊“AI全景戰略”的關鍵一環。在超級應用(微信、QQ)與底層大模型(混元)之間,ima承擔了垂直場景的智能中樞角色:向上連接用戶個性化需求,向下整合多模態技術能力。其“三層鏈路”實質是騰訊對AI時代信息價值鏈的重新定義。

丨一名觀眾在WAIC現場體驗ima
ima的爆發離不開騰訊生態的"加持"。在內容端,它可以獨家索引5000萬篇公眾號文章,將微信生態的優質內容轉化為知識庫素材;在工具端,與騰訊文檔、騰訊會議聯動,會議紀要可自動解析為知識單元,文檔創作時能實時調用知識庫內容;在算力端,騰訊云智算平臺提供從訓練到推理的全流程支持,保障千萬級知識庫的高效運轉。這種"產品-內容-算力"的協同,根植于騰訊獨有的生態優勢,也是ima爆發的深層原因。
二、ima的迭代密碼
ima的爆發式增長絕非簡單的功能疊加,而是完成了一場對“知識生產力”的底層重構。它的迭代路徑圍繞“讓知識從靜態存儲轉化為動態生產力”這一命題,實現了知識活化—智能協同—生態共振的三階質變。這三個階段層層遞進,既破解了AI時代知識管理的核心矛盾,也構建了其難以復制的競爭壁壘。
1.知識活化:破解“收藏即遺忘”的困境,2024.10-2025.2
互聯網時代的知識管理,往往困在“存儲≠使用”的魔咒中:我們收藏了無數公眾號文章、PDF報告、會議筆記,卻在需要時如同大海撈針——不是“知識不夠”,而是“知識無法被激活”。ima的第一階段革命,正是通過知識的“可計算化改造”,讓沉睡的信息變成能被AI理解、調用的“活知識”。
其底層邏輯是“非結構化內容→結構化知識單元”的轉化。傳統筆記工具雖能存儲文檔,卻無法讓機器真正“讀懂”內容;而ima通過三層架構中的底層知識庫,將用戶上傳的文檔、圖片、公眾號文章甚至截圖,經過OCR解析、語義切片后,轉化為可被理解和調用的知識單元。例如,上傳一份“2025年AI趨勢報告”,ima不僅能提取關鍵數據,還能識別“大模型”“RAG技術”等核心概念的關聯,生成可視化知識圖譜——這相當于給知識裝上了“GPS定位”,讓AI能隨時精準調用。這種“知識活化”能力,大幅提升效率的同時,也保證了回答準確性。
這一階段的本質,是將知識從“被動存儲介質”轉化為“主動響應的智能單元”,為后續的生產力釋放打下基礎。

丨ima和微信、騰訊元寶、QQ共同作為騰訊AI應用登上《新聞聯播》
2.智能協同:雙引擎驅動的知識提效,2025.2-2025.5
當知識完成“可計算化改造”,如何讓其在不同場景下高效協同?ima的第二階段突破,在于構建了“雙引擎+全鏈路”的智能協同網絡:通過模型策略創新和場景滲透,讓知識從“單點調用”升級為“全鏈路賦能”。
在模型層面,ima采取“自研+開源”的雙引擎戰略:同時接入騰訊混元大模型和DeepSeek-R1模型,用戶可以自行選擇,根據場景靈活切換。
更關鍵的是“全鏈路提效”,知識不再局限于單一工具,而是滲透到信息處理的每個環節。在“讀”的場景,ima能解析PDF文檔生成思維導圖,自動標注重點段落;在“問”的場景,用戶@知識庫即可調用特定領域知識;在“寫”的場景,AI創作功能能基于知識庫內容生成報告,并自動引用來源。
這一階段的突破,在于將“知識工具”升級為“知識協同網絡”——模型、內容、場景不再孤立,而是形成“調用-反饋-優化”的閉環,讓知識生產力實現從“點效率”到“鏈效率”的躍升。

丨WAIC現場,ima知識庫部分展示
3.生態共振:從個人工作臺到集體智慧共創,2025.5-至今
單一用戶的知識畢竟有限,如何讓千萬用戶的知識形成合力?ima的第三階段,通過“私域+公域”的知識網絡構建,讓個體知識匯入集體智慧,形成“生態共振效應”——這不是簡單的“平臺化”,而是知識生產力從“個人所有”到“集體共創”的質變。
知識號體系,是生態共振的核心引擎。它允許用戶將私域知識庫發布至“知識庫廣場”,單個知識庫最高可支持100萬人共享,且不占用個人云存儲空間。公域知識貢獻者能獲得認證、流量扶持,甚至通過數據看板查看訪問量、問答趨勢,優化內容精準度。這種機制不僅激活了多元主體參與,更重要的的是“知識復用機制”的創新:歸檔內容中的通用模塊會被AI提取為“可復用片段”,在新項目創建時自動推薦。這相當于千萬用戶的“隱性經驗”被轉化為“顯性知識組件”,形成“一人貢獻、萬人復用”的網絡效應。截至2025年7月,ima公域知識庫內容超2000萬條,私域可分享內容環比增長208%,印證了生態共振的爆發力。
這一階段的本質,是讓知識突破個體邊界,通過生態協同產生“1+1>100”的共振效應——ima不再只是個人的“第二大腦”,而是千萬用戶共同構建的“集體智慧反應堆”。
從知識活化到智能協同,再到生態共振,ima的迭代路徑揭示了AI原生應用的核心邏輯:技術創新的終極目標不是功能疊加,而是重構知識與生產力的關系,用“知識生產力躍遷”重構工作流,讓AI從“實驗室技術”變成人人可用、好用的“生產力操作系統”。當杭州錢江海關的法規條文能實時匹配群眾咨詢,當高校教授的講義能跨校賦能師生,ima證明,真正的AI革命,在于讓每個普通人都能駕馭知識、創造價值——這才是ima的秘密武器。
三、從"信息過載"到"智能涌現":ima如何重構知識工作流
ima的真正價值,不止于一款工具的成功,更意味著知識工作流的范式轉移。
1.信息獲取:從"搜索"到"涌現"
傳統搜索模式下,用戶需主動輸入關鍵詞、篩選結果、整合信息,效率低下且易遺漏。ima通過"主動知識推送"重構這一流程:比如,當用戶研究"跨境電商稅務政策"時,系統會自動關聯海關法規庫、稅務案例庫、行業報告庫,生成包含法條引用、實操建議、風險提示的"知識包"。這種"需求觸發-知識涌現"的模式,讓信息獲取從"大海撈針"變成"智能匹配"。
2.知識管理:從"文件夾"到"知識圖譜"
多數人管理知識仍停留在"文件夾分類"階段,難以發現知識間的隱性關聯。ima通過知識圖譜技術,自動識別內容中的關系:上傳一篇"AI大模型發展簡史",系統會自動關聯"GPT-4""混元""MoE架構"等節點,生成可視化腦圖,知識復用率提升大幅提升,知識也得以從“檔案柜”變身決策引擎。
3.內容創作:從"從零開始"到"知識生成"
在傳統創作流程中,作者需先搜集資料、梳理邏輯、組織語言,耗時耗力。ima將這一過程壓縮為"知識調用-結構化生成-個性化編輯"三步:寫行業分析時,可直接@"互聯網行業數據庫"獲取最新數據;做PPT時,腦圖工具能基于知識庫自動生成大綱;甚至學術論文的文獻綜述,系統也能整合相關研究并標注引用。
ima的“邊問邊看、邊搜邊記”,區別于傳統“檢索-閱讀-創作”的線性流程。用戶可在同一界面完成:上傳百頁文獻-AI生成腦圖-調用案例庫寫作-自動排版輸出,知識工作從“分階段流水線”進化為“實時交互式創作”。
四、“活”知識的未來
ima知識號生態的爆發僅是開端,何毅進在演講中的展望“讓有用可靠的信息在AI時代流動”大有深意。分析不難發現,ima已在三個維度埋下伏筆:
認證體系構建信任壁壘:首批百家加V知識號(如錢江海關、東吳證券)形成權威性標桿;
商業化機制醞釀價值兌現:留言功能、數據分析工具已為創作者變現鋪路;
多端協同擴大生態半徑:QQ瀏覽器QBot、騰訊元器智能體平臺與ima共享混元底座,實現B/C端協同覆蓋。
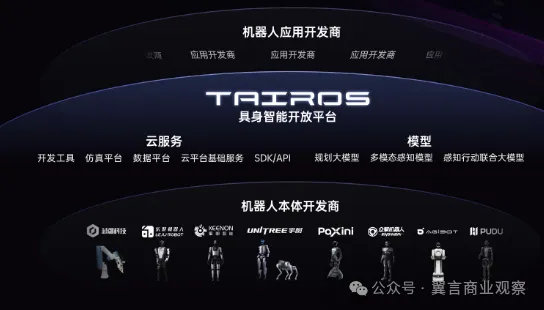
丨騰訊在WAIC推出國內首個模塊化具身智能開放平臺Tairos
AI時代,知識流動的意義值得重新打量。
WAIC展館的另一端,騰訊Robotics X實驗室發布的具身智能平臺Tairos正嘗試為機器人裝上“大腦”。不遠的未來,AI終將從數字世界走向物理世界。
而ima的探索或許更為深遠:當海關法規、投研報告、教學講義通過知識號流動起來,當2000萬篇內容在RAG鏈路中持續自我更新,知識本身獲得了“生命”。這種生命力不體現為機器的肢體運動,而體現為思想的加速碰撞與再生。
1.TMT觀察網遵循行業規范,任何轉載的稿件都會明確標注作者和來源;
2.TMT觀察網的原創文章,請轉載時務必注明文章作者和"來源:TMT觀察網",不尊重原創的行為TMT觀察網或將追究責任;
3.作者投稿可能會經TMT觀察網編輯修改或補充。
